Hmotnostní spektrometry s vysokým rozlišením a přesnou hmotou (high-resolution, accurate mass, HRAM) umožňují zaznamenat obrovské množství informací; několikrát za vteřinu změří s vysokou citlivostí hmotnostní spektrum přes široký rozsah m/z (i několik tisíc amu). Získáme tak záznam o všech ionizovatelných látkách, které jsou ve vzorku přítomny. Toho lze využít při tzv. screeningu, tedy hledání velkého množství neočekávaných nebo dokonce neznámých látek. Jak ale v tak komplikovaných datech, jaké HRAM spektrometry generují, najít látky, které nás zajímají? V lepším případě máme k dispozici seznam látek (často daný legislativou) a takové analýze se říká cílený screening. V tom horším případě (minimálně mnohem náročnějším) nevíme vůbec nic a jedná se tedy o necílenou analýzu. V takových případech je vždy nutné mít referenční vzorek a porovnat profil látek ve vzorku vyšetřovaném a referenčním. Tabulka 1 shrnuje typy LC/MS analýz, jaké informace jsou typicky k dispozici a jaký typ instrumentace je vhodné použít.
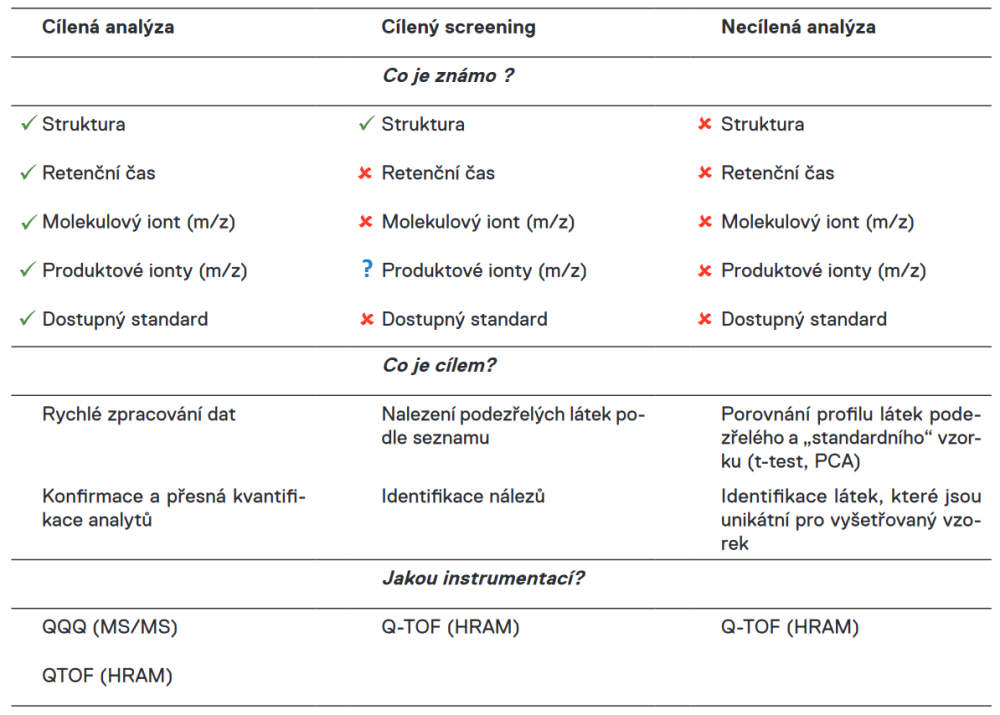
Cílený screening
Při cíleném screeningu máme k dispozici seznam látek, které ve vzorcích hledáme. Protože se tedy nejedná o látky neznámé, máme alespoň nějakou informaci o analytu (struktura, hmotnost nebo i produktové spektrum), avšak obvykle není k dispozici analytický standard ani informace o retenčních časech sloučenin (pokud bychom je měli, bude se jednat spíše o cílenou analýzu). Informace o analytech jsou často dostupné ve formě databází nebo knihoven.
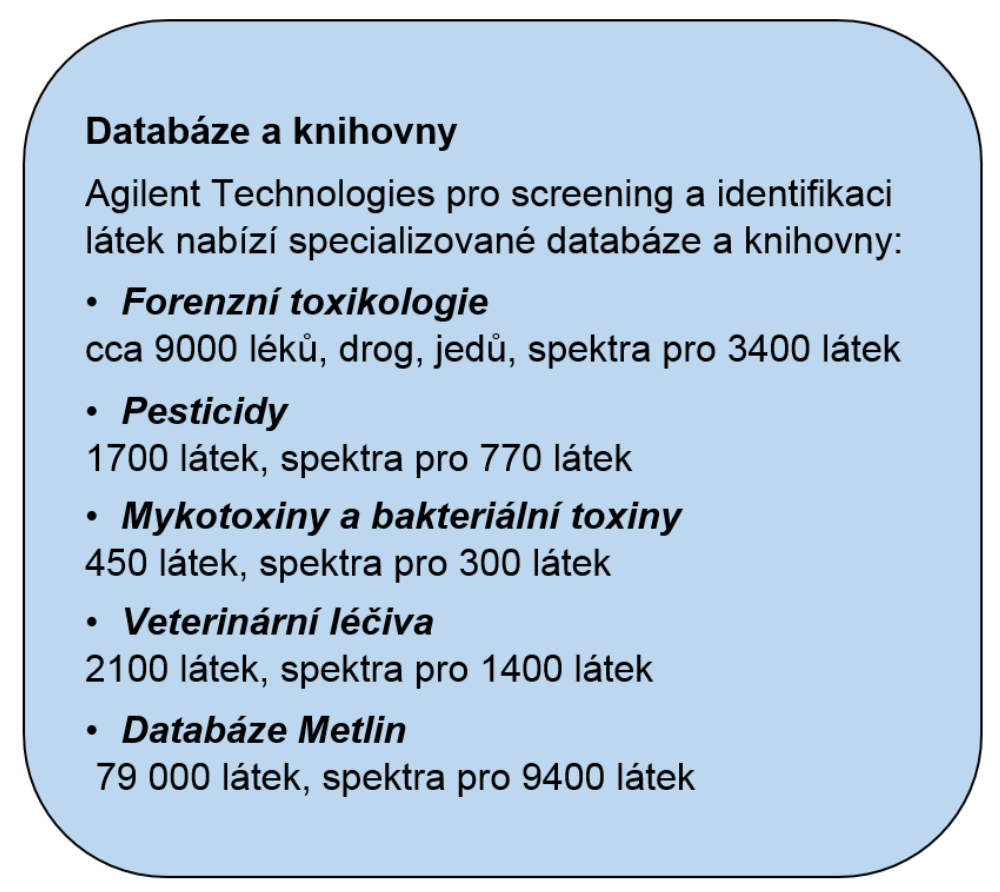
Pod pojmem databáze rozumíme soubor informací o dané sloučenině jako je název látky (běžný i IUPAC), CAS #, sumární i strukturní vzorec. Knihovna kromě těchto informací obsahuje i naměřená produktová spektra získaná při několika kolizních energiích (korigované na přesnou teoretickou hmotu) a nese zároveň informaci o polaritě a m/z prekurzoru.
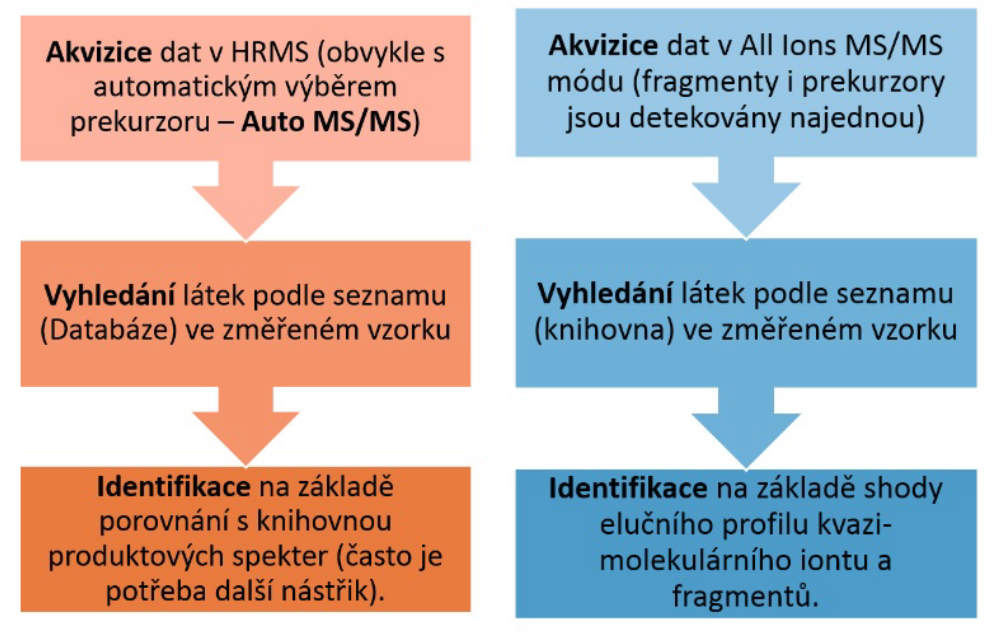
Pro cílený screening se využívají dvě strategie, které se liší způsobem akvizice dat a identifikací látek (viz Obrázek 1).
Strategie Auto MS/MS
První strategie využívá pro screening akviziční režim Auto MS/MS. V režimu Auto MS/MS je nejprve během několika desítek milisekund změřeno plné MS spektrum bez fragmentace, ve kterém je podle intenzity vybráno několik prekurzorů. Pro ty jsou následně změřena produktová spektra. Díky tomu, že technologie QTOF umožňuje velmi rychlý sběr dat, lze celý popsaný cyklus zvládnout několikrát za vteřinu a dosáhnout tak dostatečného prokreslení i úzkých píků z UHPLC.
Při zpracování dat vyhodnocovací algoritmus softwaru MassHunter v prvním kroku prohledá MS spektra, ze kterých se vyextrahují ionty odpovídající sloučeninám z databáze, popř. sub-databáze. Aby byla látka identifikována jako možná shoda s databází, je hodnocena nejen shoda přesné hmoty monoizotopického iontu, ale také přesnost hmoty jednotlivých izotopů, jejich poměry a spacing, tj. vzdálenost od monoisotopic kého iontu – viz Obrázek 2.
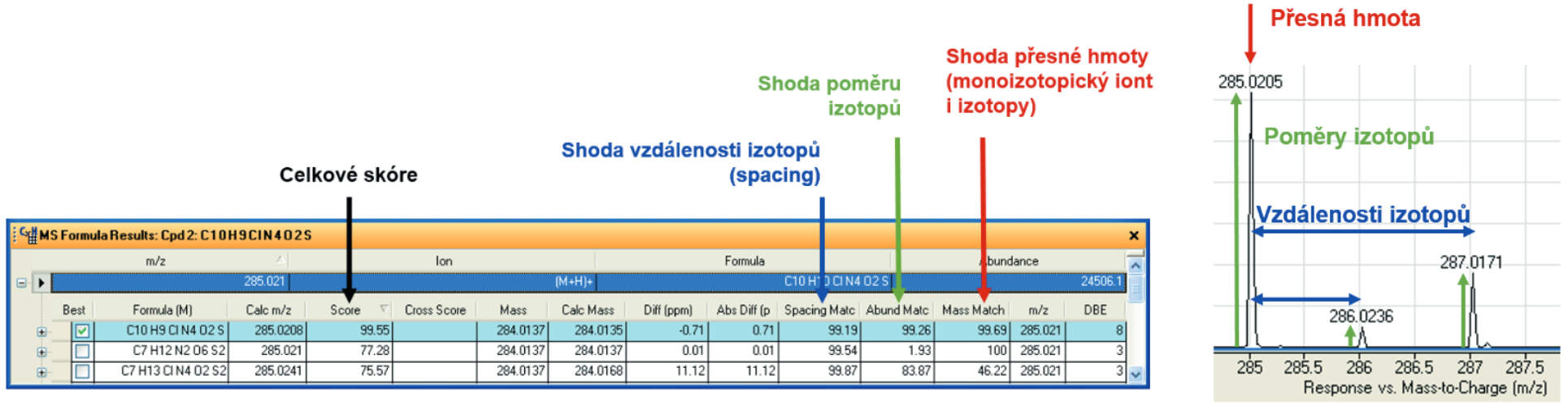
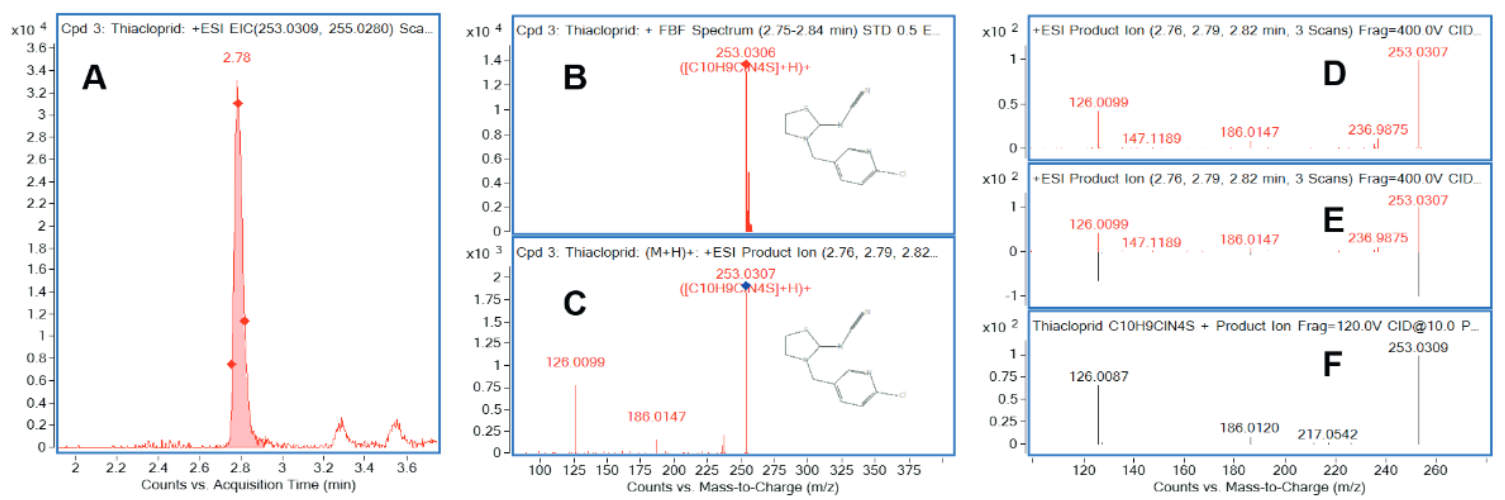
V druhém kroku jsou změřená produktová spektra nalezených látek porovnána se spektry v knihovně, čímž je konfirmována nebo vyloučena identita analytu. Pokud jsou produktová spektra v knihovně získána na stejném typu přístroje, nebo alespoň na přístroji se stejnou geometrií kolizní cely, je shoda velmi dobrá. V Obrázku 3 je reálný příklad identifikace sloučeniny thiacloprid na základě shody molekulového iontu (přesná hmota a izotopová obálka) a produktového MS spektra s knihovnou.
Pokud pro danou sloučeninu není v knihovně k dispozici produktové MS spektrum, není situace ztracená. Agilent Technologies dodává ke QTOF systémům softwarový nástroj Molecular Structure Correlator, který na základě fragmentačních pravidel hodnotí pravděpodobnost, že změřené produktové spektrum vzniklo z předpokládané struktury.
Lze se tedy na základě MS/MS spektra například rozhodnout mezi dvěma sloučeninami s totožným sumárním vzorcem nebo dokonce z internetových databází automaticky stáhnout všechny možné strukturní vzorce a seřadit je podle vypočtené pravděpodobnosti, podle počtu citací v literatuře apod.
Strategie All ions MS/MS
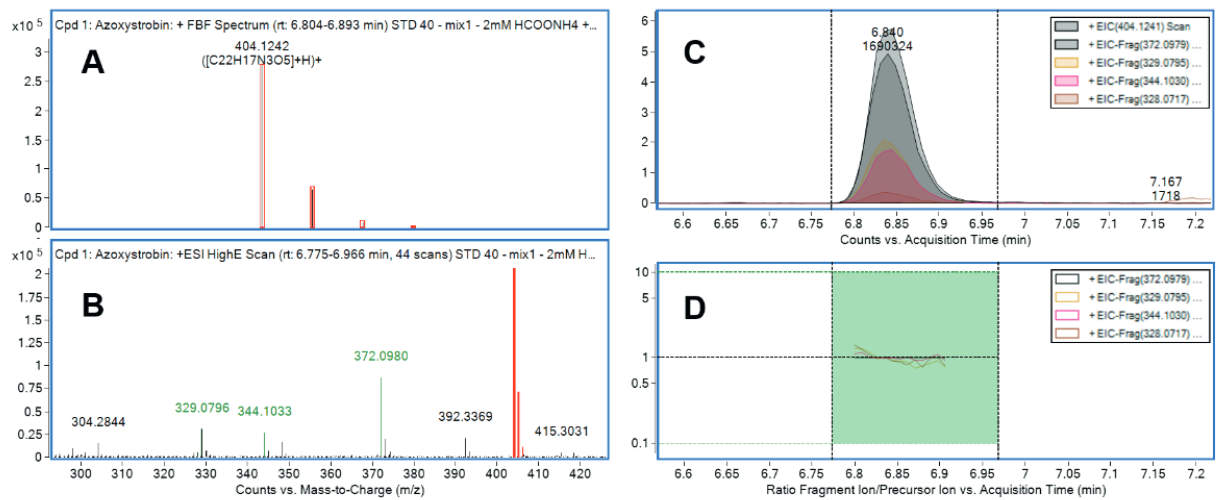
Druhá strategie cíleného screeningu (viz Obrázek 1B) využívá tzv. „All Ions MS/MS“ technologii. Při „All Ions MS/MS“ je kvadrupól v přístroji QTOF propustný pro všechny ionty a pouze se mění napětí v kolizní cele. Získá se tedy záznam MS spekter bez fragmentace a MS spekter s indukovanou fragmentací všech koeluovaných látek. První krok při vyhodnocení dat je identický s Auto MS/MS režimem, tedy v datech bez kolize jsou podle databáze vyhledány podezřelé látky. Identifikace látek je však zcela odlišná – z produktových spekter v knihovně jsou použity přesné hmoty fragmentů a pro ně se vyextrahují chromatogramy. Poté je hodnoceno tzv. „koeluční skóre“, tedy do jaké míry se překrývá chromatografický pík molekulového iontu a fragmentů, které charakterizují danou sloučeninu – viz Obrázek 4.
Výhoda postupu „Auto MS/MS“ před „All Ions MS/MS“ spočívá v naprosto jednoznačné identifikaci látek a dále i ve výše zmíněné možnosti identifikace látek, které nemají produktové spektrum v knihovně. Jistou nevýhodou je, že pokud se automaticky nevybere prekurzor analytu v režimu Auto MS/MS, je nezbytné pro konfirmaci analytu změřit produktové spektrum dodatečně. V případě All Ions MS/MS jsou produktové ionty vždy změřeny, ale chybí vztah mezi konkrétním prekurzorem a jeho produktovými ionty.
Z toho důvodu lze identifikovat pouze látky, pro které je v knihovně analytů již produktové spektrum změřené. Zároveň je přístup s All Ions MS/MS akvizicí vhodnější pro kvantifikaci látek.
Necílený screening
Úkolem necílené analýzy je nalézt a identifikovat „vše“ co je obsaženo ve vzorku. To představuje nesmírně náročný úkol, navíc řada sloučenin ve vzorku není ničím zajímavá. V praxi je tedy vhodné specifikovat látky, které jsou nějak zajímavé nebo důležité. Nejčastější cestou, jak tyto látky nalézt je tzv. diferenční analýza, kdy se porovnává profi l molekul mezi dvěma vzorky nebo dvěma skupinami vzorků a hledají se látky, které představují významný rozdíl mezi nimi. Například lze zjistit kontaminanty, které se dostávají z továrny/města do řeky analýzou vzorků vody nad místem znečištění a pod ním. Stejně tak lze sledovat odlišnosti mezi šaržemi výrobků apod.
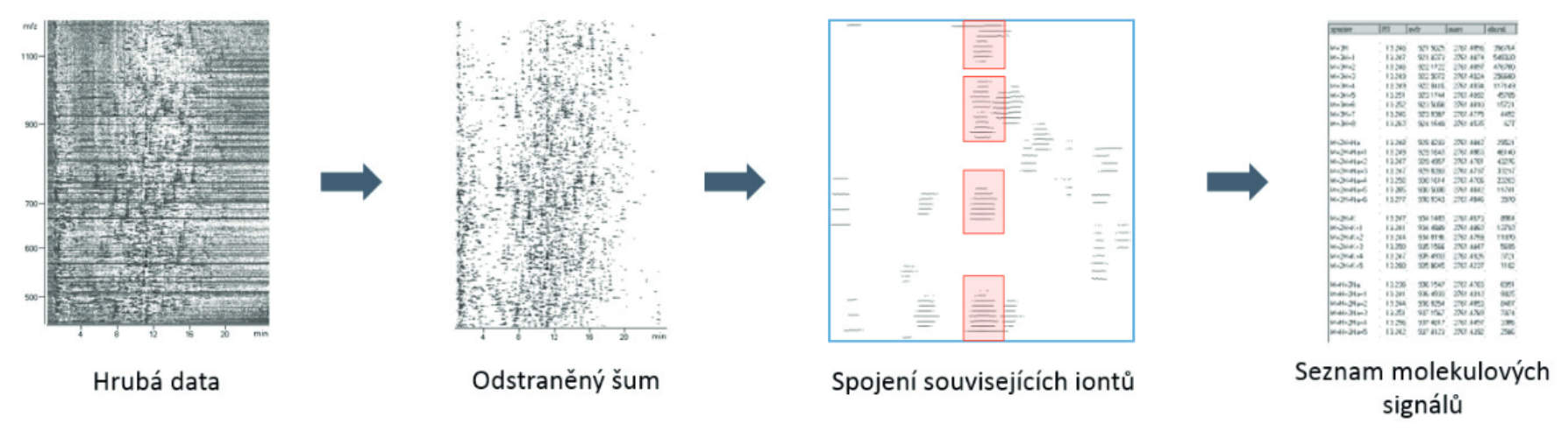
Při necíleném screeningu jsou ze změřených vzorků vyextrahovány píky látek, tzv. peak picking. Jedná se o poměrně komplikovaný algoritmus, který vyhledává signály odpovídající jedné sloučenině (různé adukty, odlišné nábojové stavy, dimery, fragmenty) a spojuje je do tzv. molekulových signálů (features), kde společným jmenovatelem všech iontů je jejich neutrální hmotnost. Aby bylo možné porovnat látky přítomné ve vyšetřovaném vzorku a v referenci, je potřeba provést jejich zarovnání (tzv. alignment) podle retenčního času a zároveň neutrální hmotnosti. Pro úspěch celé diferenční analýzy jsou nesmírně důležité právě první dva kroky, tedy extrakce signálů a alignment. Při extrakci signálů je nezbytné, aby softwarový algoritmus správně našel a sloučil všechny signály iontů příslušejících danému analytu. Pokud by látka, i když přítomná v obou vzorcích, byla vyextrahovaná pouze v jednom z nich, dojde k tomu, že z diferenční analýzy vyjde jako unikátní. Ke stejnému výsledku dojde i v případě, kdy je látka vyextrahovaná z obou vzorků, ale během alignmentu je vyhodnocena jako dvě odlišné (např. kvůli posunu retenčního času).
Na uvedených příkladech je vidět, že problémem necíleného screeningu obvykle není nalezení rozdílů mezi vzorky, ale minimalizace vzniku falešných diferencí. To lze řešit dvoukolovou extrakcí látek, kdy v prvním kole dojde k necílené extrakci signálů ze všech vzorků, provede se alignment, ale ionty látek ze všech vzorků jsou v druhém kole znovu, cíleně vyhledány ve změřených datech (tzv. rekurzní extrakce). Tím je zajištěno, že budou porovnávány stejné analyty, a že i málo intenzivní látky, které v jednom ze vzorků nebyly nalezeny necílově, budou vyextrahovány. Tím pádem výsledkem diferenční analýzy budou skutečně pouze analyty unikátní pro jeden ze vzorků.
Pro usnadnění necíleného screeningu nabízí Agilent Technologies jednoduchý softwarový nástroj Mass Profiler, který automaticky provádí výše zmíněnou dvoukolovou extrakci látek, a poskytuje tak kvalitní výsledky bez falešně pozitivních chyb. Kromě toho obsahuje řadu možností grafického zobrazení nalezených diferencí, lze pro ně vypočítat sumární vzorce nebo je identifikovat pomocí různých offline nebo online databází. To vše při zachování velmi jednoduchého rozhraní, které nevyžaduje hlubší znalosti statistické analýzy.
Závěr
Je zřejmé, že při cíleném screeningu je úspěch podmíněn především rozsahem použitých databází a knihoven; analyty, které v databázi nejsou, není možné nalézt a reportovat. Kromě počtu analytů jde i o informace k nim dostupné. Především jsou podstatná kvalitní MS/MS spektra pro snadnou konfirmaci suspektních nálezů, protože bez konfirmace není validní výsledek. Kromě toho je důležitá i zkušenost analytika s danou skupinou látek, protože i přes moderní software a obsáhlé databáze látek je to nakonec on, kdo rozhoduje, jakým způsobem se bude vzorek analyzovat a zda nalezená látka je skutečně hledaný analyt nebo interference z matrice.
Necílená analýza je mnohem náročnějším úkolem a klade ještě vyšší nároky na zkušenosti analytika než cílený screening. Klíčovým faktorem je zde kvalitní extrakce molekulových signálů a příprava dat před samotnou diferenční analýzou. K tomu jsou využívány pokročilé algoritmy, které zajišťují minimalizaci falešně pozitivních píků a zároveň umožní vyhledávat signály i na nízké úrovni intenzit. Obvykle obávaná statistická analýza je až pomyslná „třešnička na dortu“. Samostatnou kapitolou je potom identifikace diferencí, kde se používají obsáhlé offline i online databáze kombinované s manuální interpretací produktových spekter látek a všechny dostupné informace z literatury.
V případě dalších dotazů neváhejte kontaktovat:
Jitka Zrostlíková, produktový specialista, jitka.zrostlikova@hpst.cz
Ondřej Lacina, aplikační specialista, ondrej.lacina@hpst.cz
Publikováno v ChromAtoMol #3 a na stránkách LabRulezLCMS